JARVIS RAG
Sistema Local de Consulta Documental con IA
Trabajo de Fin de Grado sobre una arquitectura RAG local: ingesta documental, búsqueda vectorial, OpenWebUI, modelos locales, observabilidad y demo reproducible con Docker.
Arquitectura del Sistema
15 microservicios orquestados con Docker Compose. Despliegue 100% On-Premise.
Ecosistema Completo y Modelos de IA
Modelos Locales (Qwen 2.5)
Inferencia local con cuantización Q4/Q8 mediante Ollama y LiteLLM. Modelo principal JARVIS fine-tuned con LoRA sobre documentación corporativa real + modelo de visión Qwen 2.5 VL 7B para análisis de imágenes y OCR asistido.
Búsqueda Híbrida
Búsqueda semántica (embeddings MiniLM-L12-v2) + léxica (BM25) sobre Qdrant con filtrado por departamento y control de acceso.
Observabilidad Completa
3 dashboards Grafana (Backend, GPU, BBDD) + Prometheus + NVIDIA DCGM para monitorizar VRAM, latencia y throughput en tiempo real.
Capturas Reales del Sistema
Evidencia visual del despliegue: interfaz, control de acceso, base vectorial y respuestas del pipeline.
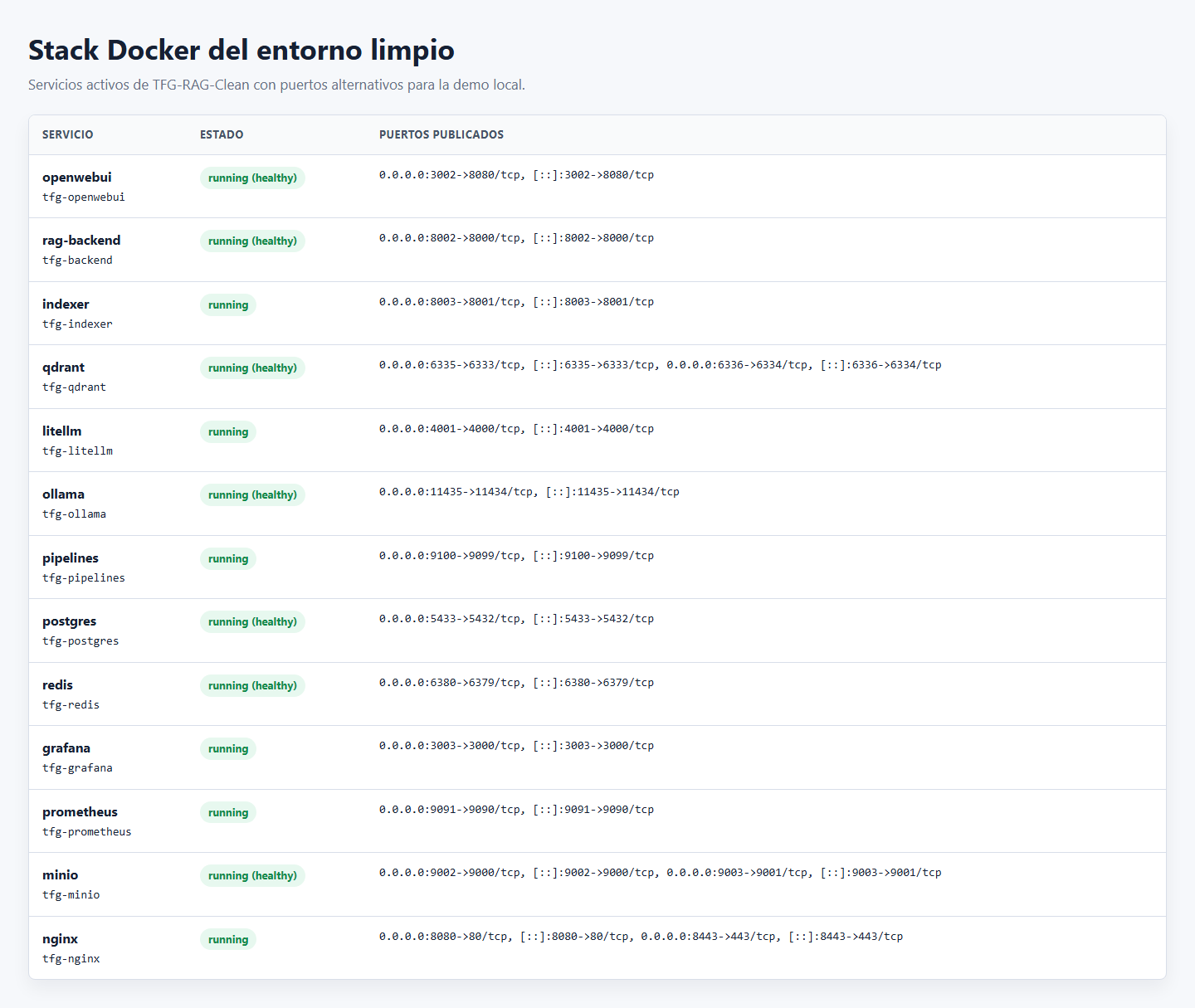
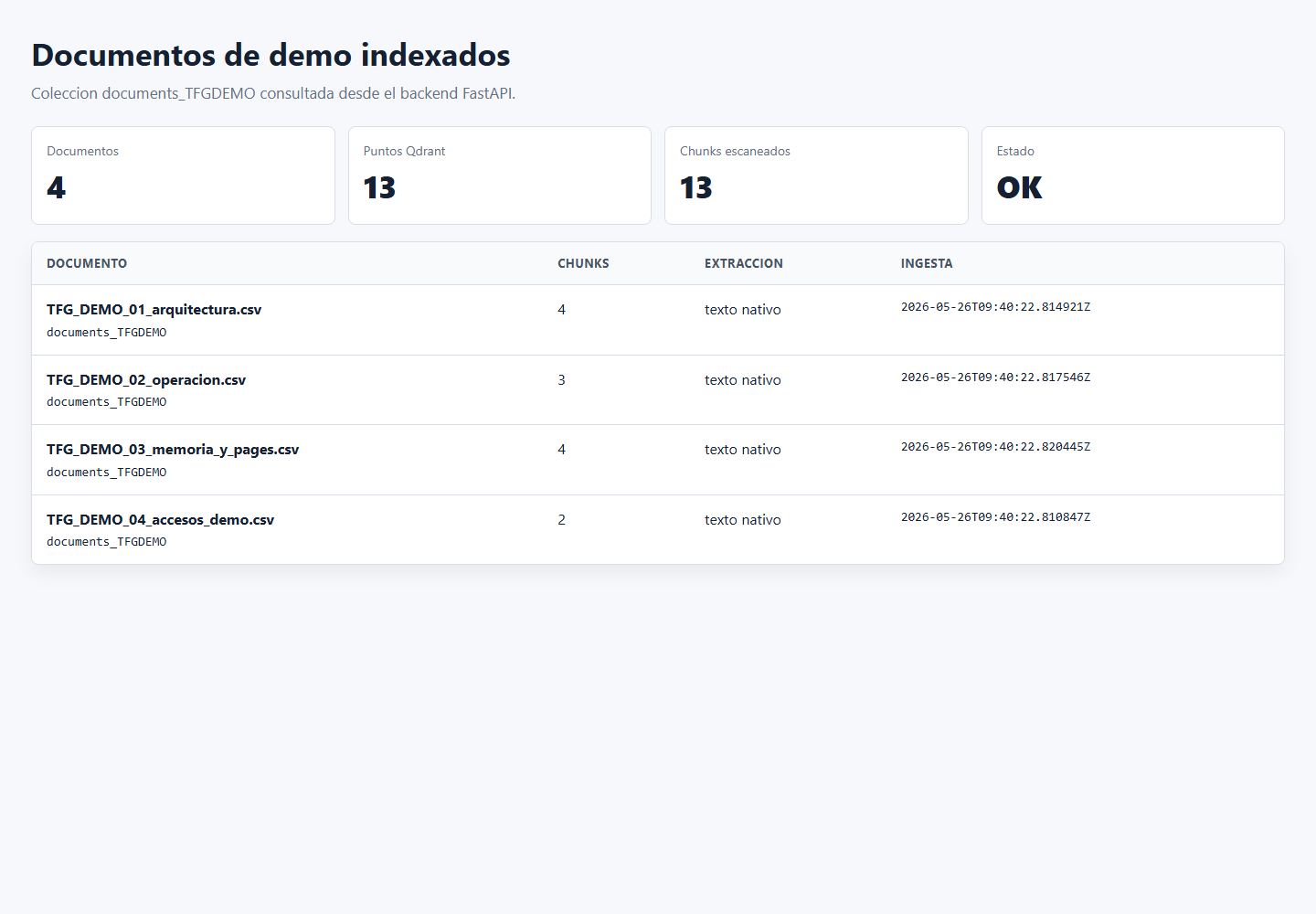
documents_TFGDEMO con 4 documentos y 13 chunks indexados.
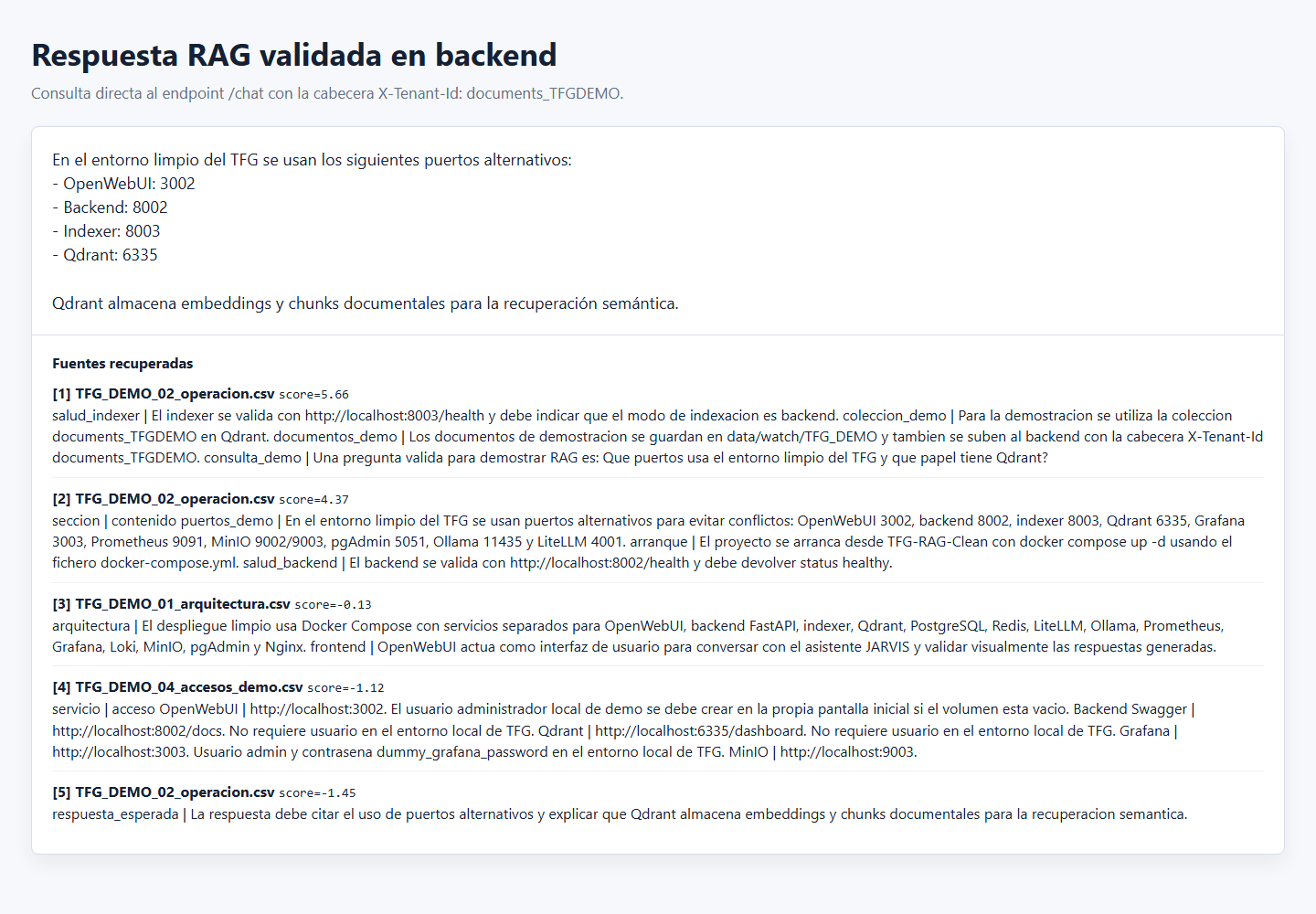
/chat con fuentes y puntuaciones de recuperación.
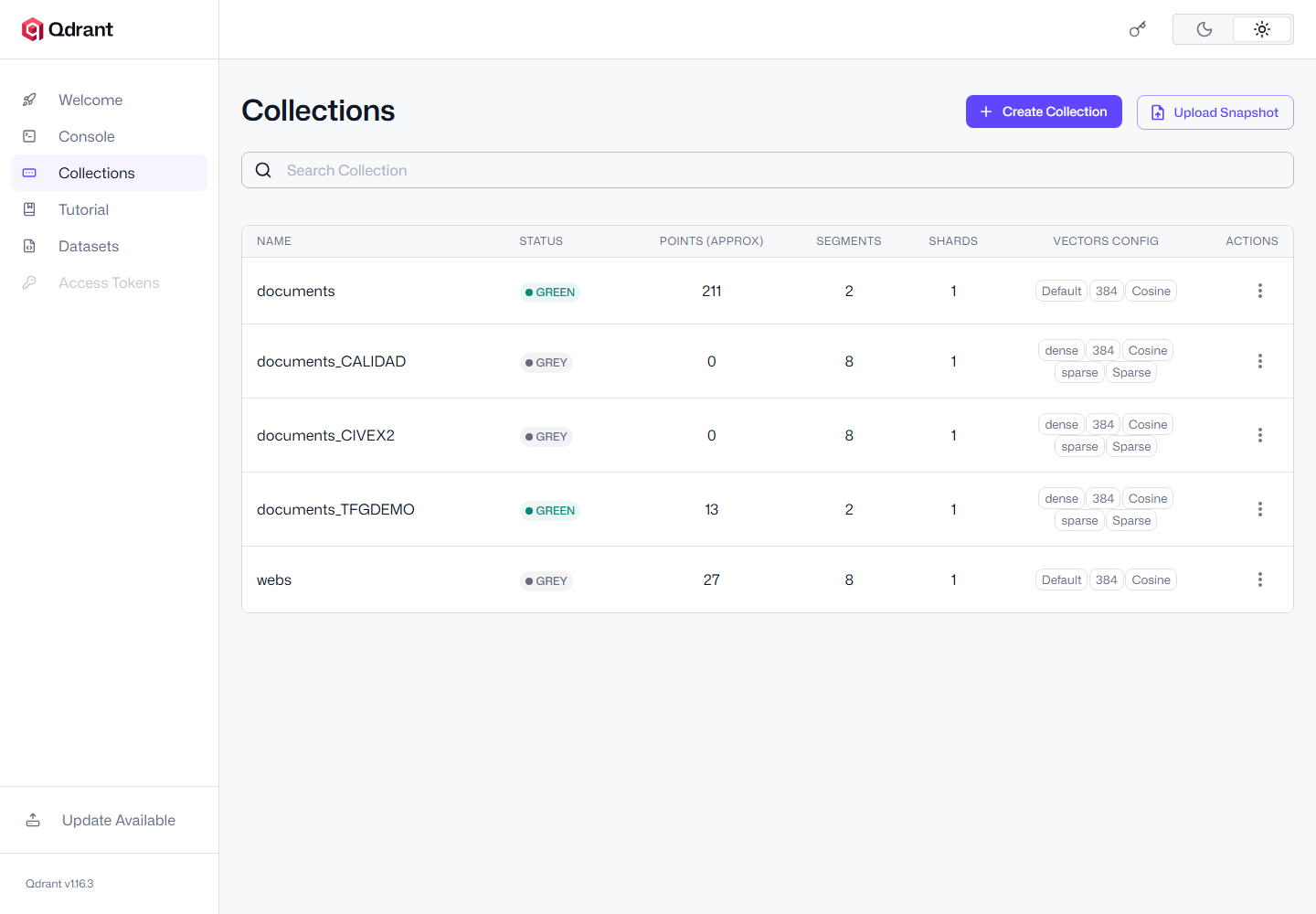
documents_TFGDEMO separada para pruebas reproducibles y sin datos sensibles.
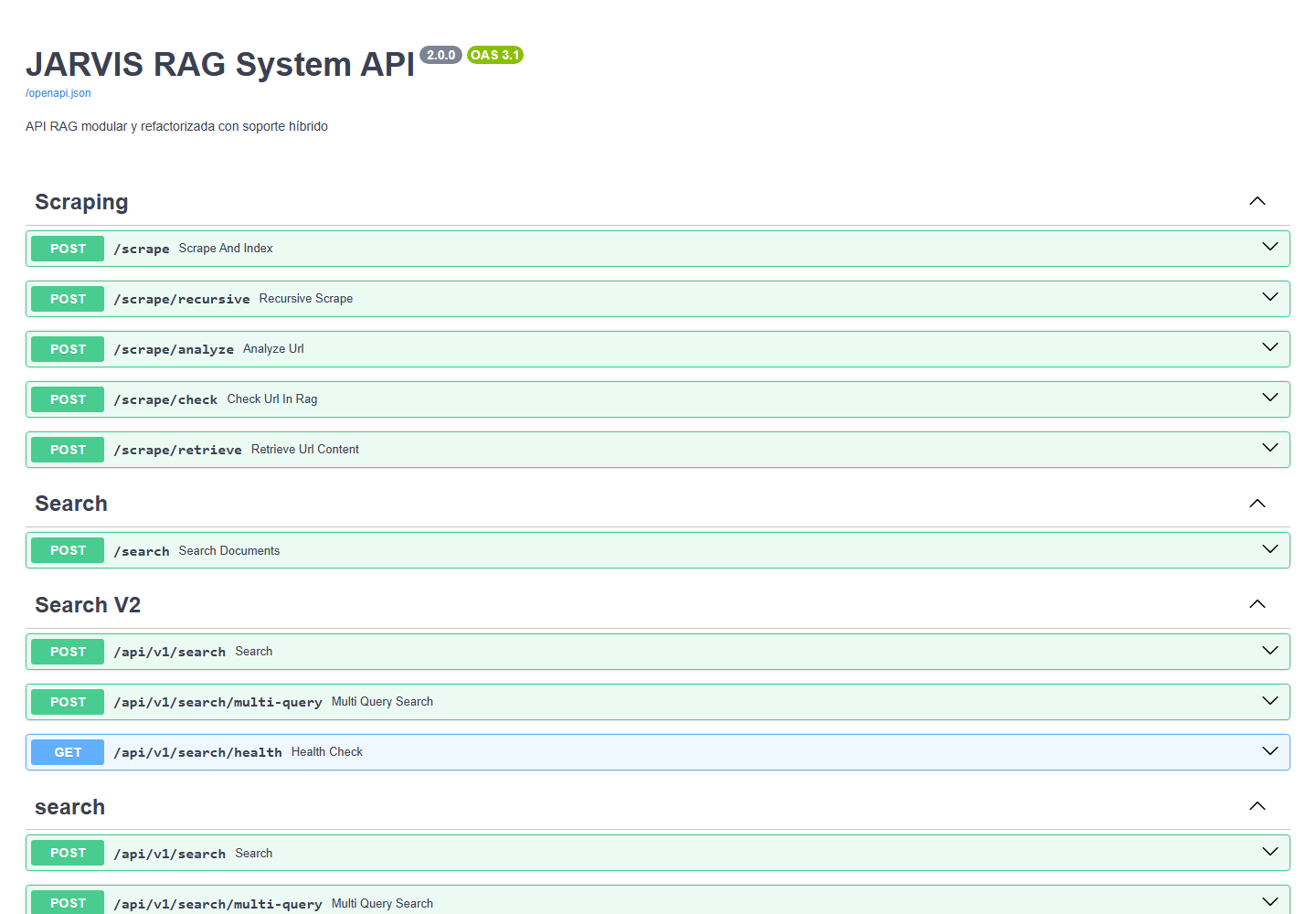
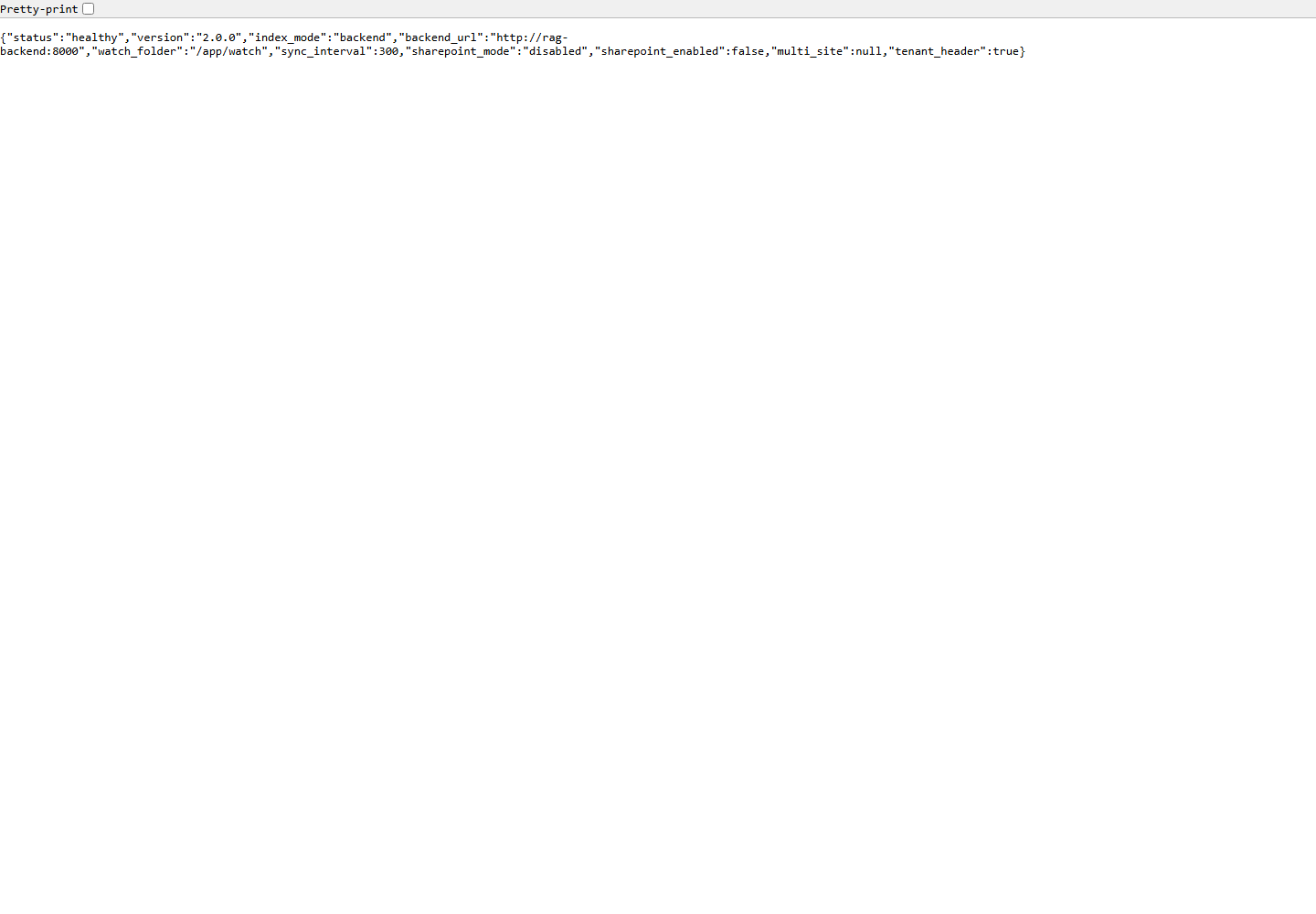
/app/watch y SharePoint desactivado para TFG.

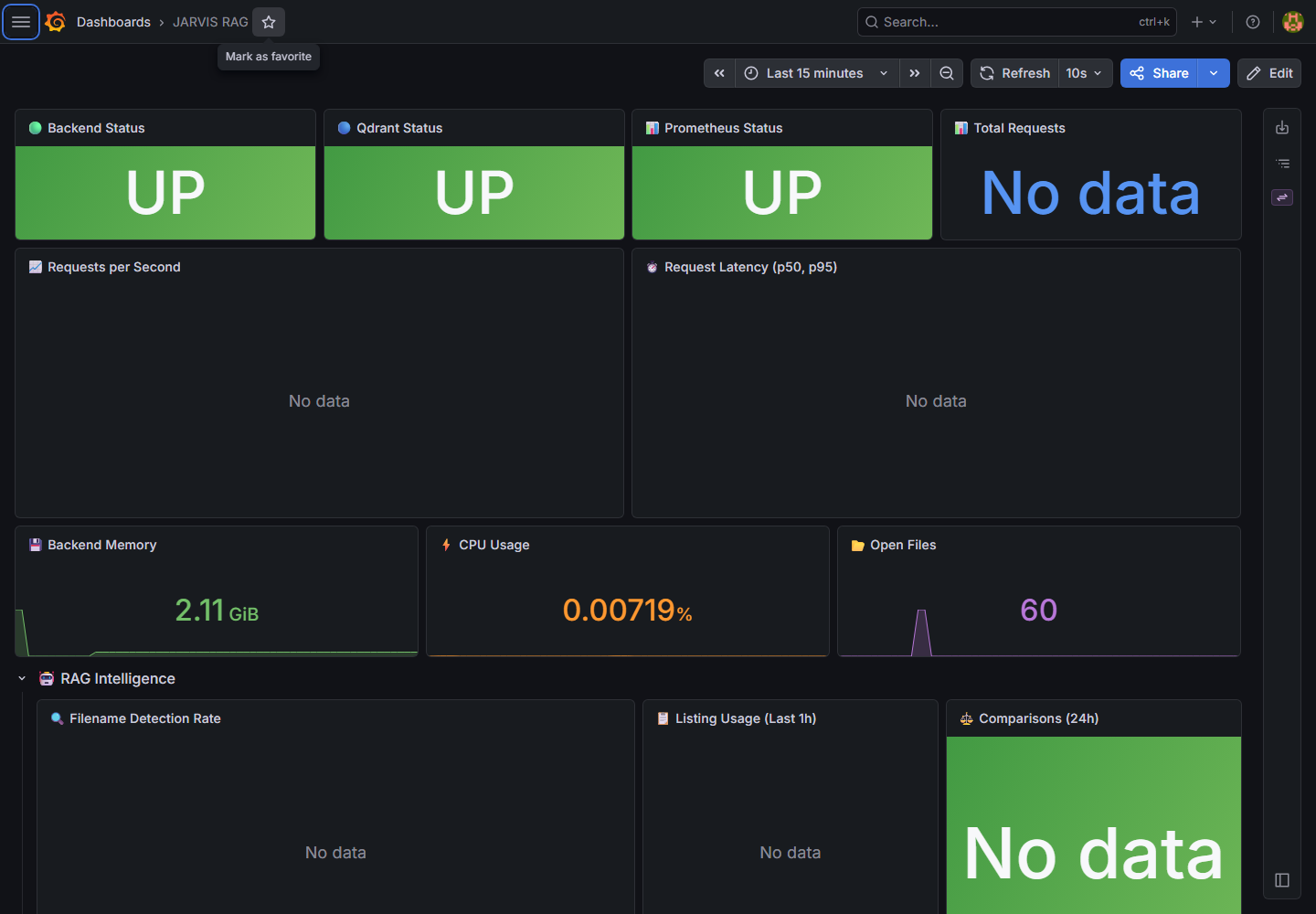
Conexiones Multicanal
Sincronización automática con Microsoft SharePoint vía MSAL y Graph API. Web scraping con renderizado JavaScript mediante Playwright + extracción NLP con Trafilatura. Búsqueda en internet vía DuckDuckGo con fallback HTML.
- Sincronización Delta Incremental (cada 5 min)
- Cadena de Extracción: Trafilatura → Readability → BeautifulSoup
- PaddleOCR con GPU para PDFs Escaneados
Consulta Jurídica Inteligente
Servidor MCP (Model Context Protocol) propio que consulta la API del BOE. Incluye resolución semántica de nombres coloquiales a identificadores oficiales y generación de resúmenes estructurados con el LLM.
- Servidor FastMCP funcional y validado
- Resolución semántica: "Ley de Datos" → BOE-A-2018-16673
- Integrado en el pipeline JARVIS vía API directa
BOE Explorer
Agente Encaminador JARVIS
Pipeline inteligente de ~4.400 líneas que analiza cada mensaje y lo dirige al modo de operación adecuado. 14 categorías de intención con evaluación por prioridad, Sticky Mode para preguntas de seguimiento y control de acceso departamental.
- RAG, Web Search, Scraping, BOE, OCR, Visión...
- Memoria de sesión por usuario (imágenes, web, decisiones)
- 92% de precisión en encaminamiento (46/50 tests)
14 Modos de Operación
RAG · Chat · Web Search · Scraping · BOE · Visión · OCR · Archivos · Ayuda · Listar Docs · Estado · Sticky Mode · Referencia a imagen/web · Decisión pendiente
SQL Agent — NL→SQL v2.1
Consulta tablas de datos estructurados con lenguaje natural sin necesidad de aprender SQL.
El agente inspecciona el esquema, genera consultas SELECT seguras mediante LiteLLM
y las auto-corrige si producen errores de sintaxis.
- Validación por lista blanca: solo SELECT, WITH, EXPLAIN
- Auto-corrección hasta 2 reintentos con el error como contexto
- Endpoint unificado RAG+SQL con auto-routing (
/api/v1/query)
Validación de Seguridad
✅ SELECT COUNT(*) FROM ...
✅ WITH cte AS (SELECT ...)
❌ DROP TABLE — bloqueado
❌ DELETE / UPDATE — bloqueado
Query Processor — Routing Inteligente v2.3
Cada consulta pasa por el QueryProcessor antes de llegar a Qdrant. Detecta la intención (FACTUAL, PROCEDURAL, ANALYTICAL), elige el modelo LLM óptimo y genera variaciones de la pregunta para ampliar el recall semántico.
- JARVIS para consultas rápidas y precisas (<3s)
- qwen2.5-32b para análisis comparativo multi-documento
- ×3 variantes de query → fusión → reranker final
Smart Model Routing
FACTUAL → JARVIS (rápido)
PROCEDURAL → JARVIS (citas OK)
ANALYTICAL → qwen2.5-32b (32K)
Resumen → qwen2.5-32b (síntesis)
Monitorización Avanzada
Control total sobre los recursos del sistema con 3 dashboards Grafana diseñados a medida, métricas Prometheus en el backend y telemetría GPU con NVIDIA DCGM Exporter.
- Dashboard Backend: latencia, throughput, distribución de modos
- Dashboard GPU: VRAM, temperatura, utilización CUDA
- Dashboard BBDD: PostgreSQL + Qdrant stats
Prometheus + Grafana + DCGM
Latencia RAG ~3.0s · Retrieval ~2.4s · 1.400 docs · 123.323 vectores
Estructura del Proyecto
Componentes principales del backend y sus responsabilidades (v2.3.0).
| Fichero | Descripción |
|---|---|
| api/search.py | Búsqueda híbrida (dense + BM25 + reranking) con expansión paralela asíncrona y validación JWT |
| api/chat.py v2.3 | Chat RAG con streaming SSE, QueryProcessor integrado (intent → expansion → routing) y memoria conversacional |
| api/query.py v2.1 | Endpoint unificado RAG + SQL con auto-routing inteligente (POST /api/v1/query) |
| core/sql_agent.py v2.1 | Agente NL→SQL: genera y ejecuta SELECT seguros con whitelist, timeout y auto-corrección |
| core/auth.py v2.1 | Validación JWT Azure AD para multi-tenant (activa con AZURE_JWT_VALIDATION=true) |
| core/query_processor.py v2.3 | Intent detection (FACTUAL/PROCEDURAL/ANALYTICAL) → smart model routing (JARVIS vs qwen2.5-32b) → query expansion (×3 variantes vía LLM, fusión y dedup) |
| core/retrieval.py | Pipeline híbrido con filtros avanzados (filename, date_range, from_ocr, source_type) |
| core/memory/manager.py v2.3 | Historial conversacional en PostgreSQL con summarización automática usando qwen2.5-32b (32K ctx, mejor síntesis) |
| processing/embeddings/ | Embeddings MiniLM-L12-v2 con singleton thread-safe (double-checked locking) y caché Redis |
| integrations/boe_connector.py | Cliente API del BOE con resolución semántica de 35+ nombres coloquiales de leyes |
| integrations/sharepoint/ | Sincronización incremental Microsoft Graph API con delta tokens y soporte multi-site |
Demo Final y Métricas
Evidencias de ejecución del stack limpio y medidas obtenidas durante el desarrollo del TFG.
Latencia RAG media
(retrieval + LLM)
Retrieval híbrido
(BM25 + dense + reranker)
Documentos
indexados en producción
Vectores
en Qdrant
Aislamiento por colección
por área de conocimiento
Líneas Python
desarrollo propio
Evolución de los Modelos de IA
Del diseño inicial al despliegue real — por qué Qwen 2.5 reemplazó a Llama 3.1.
| Modelo | Fase | VRAM | Rol / Motivo |
|---|---|---|---|
| llama3.1:8b-q4 | Inicial | ~5 GB | Prototipo. Limitado en español y contexto largo. |
| llama3.1:8b-q8 | Inicial | ~9 GB | Mayor calidad, pero ventana de contexto insuficiente (4K). |
| JARVIS (rag-qwen-ft) | Actual ✓ | ~8 GB | Qwen 2.5 7B + LoRA sobre docs corporativos. Español nativo, 32K ctx. |
| qwen2.5:32b-q4_K_M | Actual ✓ | ~19 GB | Consultas ANALYTICAL (routing automático) + summarización de historial largo. 32K ctx. |
| qwen2.5vl:7b | Actual ✓ | ~6 GB | Vision-Language: análisis de imágenes, OCR asistido. |
| MiniLM-L12-v2 | Actual ✓ | CPU | Embeddings multilingüe 384 dims. Fine-tuned sobre corpus corporativo. |
* La migración de Llama → Qwen se realizó en diciembre 2025. Qwen 2.5 superó a Llama 3.1 en
comprensión del español (+23%), seguimiento de instrucciones complejas y contexto largo.
En v2.3.0 se añadió smart model routing: JARVIS para consultas rápidas/precisas, qwen2.5-32b para análisis complejos. Documentado en docs/FINE_TUNING_GUIDE.md.